1. 摘要
本文介绍数据仓库中维度数据建模的过程描述,并举一个示例以加深对相关概念的理解。
2. 内容
2.1 维度模型定义
维度模型是数据仓库领域大师Ralph Kimall所倡导,他的《数据仓库工具箱》,是数据仓库工程领域最流行的数仓建模经典。维度建模以分析决策的需求出发构建模型,构建的数据模型为分析需求服务,因此它重点解决用户如何更快速完成分析需求,同时还有较好的大规模复杂查询的响应性能。
2.2 维度建模过程
第一步:选择业务过程
1、通过对业务需求以及可用数据源的综合考虑,确定对哪种业务过程开展建模工作
2、建立的第一个维度模型应该是一个最有影响的模型——它应该对最紧迫的业务问题作出回答,并且对数据的抽取来说是最容易的。
第二步:定义粒度
注:粒度是指数据仓库的数据单位中保存数据的细化或综合程度的级别,细化程度越高,粒度就越小
1、应该先优先考虑为业务处理获取最有原子性的信息而开发维度模型。原子型数据是所收集的最详细的信息,这样的数据不能再做更进一步的细分。
2、数据仓库几乎总是要求在每个维度可能得到的最低粒度上对数据进行表示的原因,并不是因为查询想看到每个低层次的行,而是因为查询希望以很精确的方式对细节知识进行抽取。
第三步:选定维度
一个经过仔细考虑的粒度定义确定了事实表的基本维度特性。同时,经常也可能向事实表的基本粒度加入更多的维度,而这些附加的维度会在基本维度的每个组合值方面自然地取得唯一的值。如果附加的维度因为导致生成另外的事实行而违背了这个基本的粒度定义,那么必须对粒度定义进行修改以适应这个维度的情景。
第四步:确定事实
确定将哪些事实放到事实表中。粒度声明有助于稳定相关的考虑。事实必须与粒度吻合。在考虑可能存在的事实时,可能会发现仍然需要调整早期的粒度声明和维度选择
2.3 维度建模的基本要素
维度建模中有一些比较重要的概念,理解了这些概念,基本也就理解了什么是维度建模。
1. 事实表
发生在现实世界中的操作型事件,其所产生的可度量数值,存储在事实表中。从最低的粒度级别来看,事实表行对应一个度量事件,反之亦然。
额,看了这一句,其实是不太容易理解到底什么是事实表的。
比如一次购买行为我们就可以理解为是一个事实,下面我们上示例。
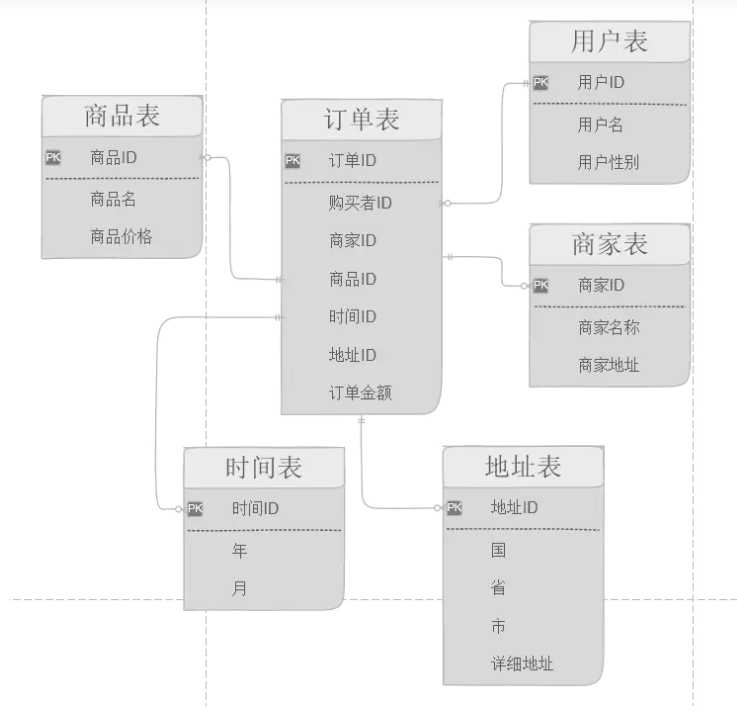
图中的订单表就是一个事实表,你可以理解他就是在现实中发生的一次操作型事件,我们每完成一个订单,就会在订单中增加一条记录。
我们可以回过头再看一下事实表的特征,在维度表里没有存放实际的内容,他是一堆主键的集合,这些ID分别能对应到维度表中的一条记录。
2. 维度表
每个维度表都包含单一的主键列。维度表的主键可以作为与之关联的任何事实表的外键,当然,维度表行的描述环境应与事实表行完全对应。 维度表通常比较宽,是扁平型非规范表,包含大量的低粒度的文本属性。
我们的图中的用户表、商家表、时间表这些都属于维度表,这些表都有一个唯一的主键,然后在表中存放了详细的数据信息。
2.4 维度建模过程举例
下面我们将以电商为例,详细讲一下维度建模的建模方式,并举例如果使用这个模型(这点还是很重要的)。
一、业务场景
假设我们在一家电商网站工作,比如某宝、某东。我们需要对这里业务进行建模。下面我们分析几点业务场景:
电商网站中最典型的场景就是用户的购买行为。
一次购买行为的发起需要有这几个个体的参与:购买者、商家、商品、购买时间、订单金额。
一个用户可以发起很多次购买的动作。
好,基于这几点,我们来设计我们的模型。
二、模型设计
下面就是我们设计出来的数据模型,和之前的基本一样,只不过是换成了英文,主要是为了后面写sql的时候来用。
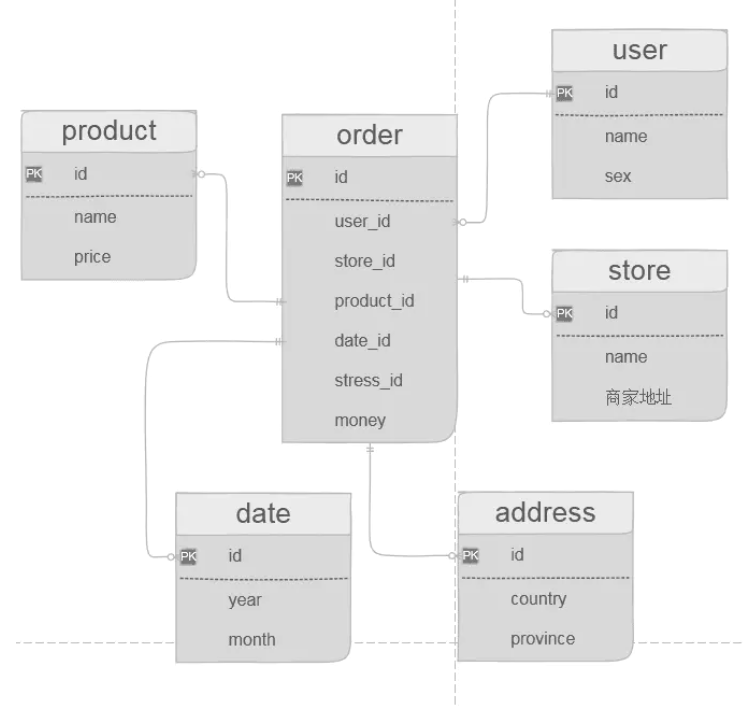
我就不再解释每个表的作用了,现在只说一下为什么要这样设计。
首先,我们想一下,如果我们不这样设计的话,我们一般会怎么做?
如果是我,我会设计下面这张表。你信不信,我能列出来50个字段!其实我个人认为怎么设计这种表都有其合理性,我们不论对错,单说一下两者的优缺点。
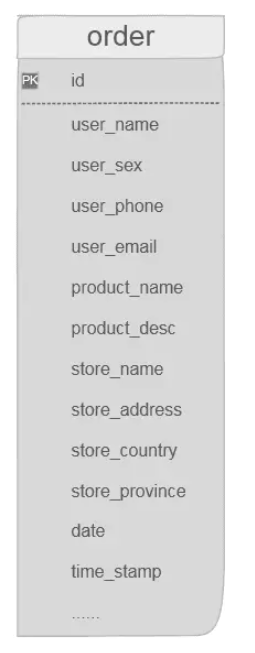
先说我们的维度模型:
数据冗余小(因为很多具体的信息都存在相应的维度表中了,比如用户信息就只有一份)
结构清晰(表结构一目了然)
便于做OLAP分析(数据分析用起来会很开心)
增加使用成本,比如查询时要关联多张表
数据不一致,比如用户发起购买行为的时候的数据,和我们维度表里面存放的数据不一致
再说我们这张大款表的优缺点:
业务直观,在做业务的时候,这种表特别方便,直接能对到业务中。
使用方便,写sql的时候很方便。
数据冗余巨大,真的很大,在几亿的用户规模下,他的订单行为会很恐怖
粒度僵硬,什么都写死了,这张表的可复用性太低。
三、使用示例
数据模型的建立必须要为更好的应用来服务,下面我先举一个例子,来切实地感受一下来怎么用我们的模型。
需求:求出2016年在帝都的男性用户购买的LV品牌商品的总价格。
实现:
SELECT
SUM(order.money)
FROM
order,
product,
date,
address,
user,
WHERE
date.year = ‘2016’
AND user.sex = ‘male’
AND address.province = ‘帝都’
AND product.name = ‘LV’
四、总结
维度建模是一种十分优秀的建模方式,他有很多的优点,但是我们在实际工作中也很难完全按照它的方式来实现,都会有所取舍,比如说为了业务我们还是会需要一些宽表,有时候还会有很多的数据冗余。
3. 参考
《Hadoop构建数据仓库实践》
漫谈数据仓库之维度建模https://zhuanlan.zhihu.com/p/27426819